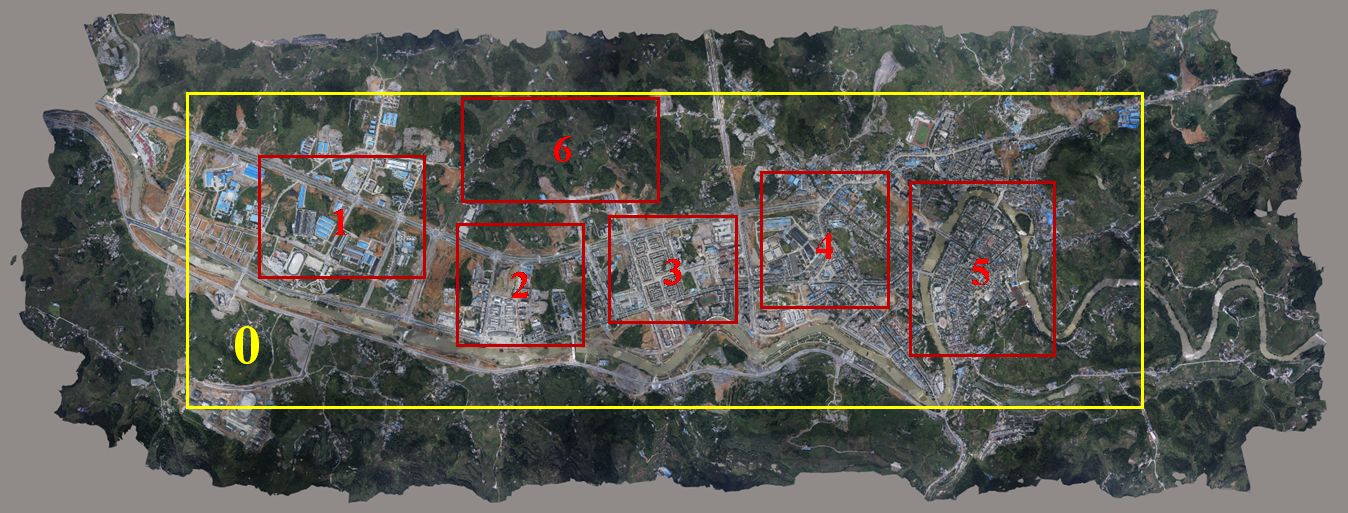
Figure 1. The dataset.
(If you meet downloading problem, please try this link, code:91ae.)
We created the synthetic aerial dataset for large-scale Earth surface reconstruction called the WHU dataset. The aerial dataset generated from a highly accurate 3D digital surface model produced from thousands of real aerial images and refined by manual editing, covering an area of 6.7×2.2 km2 over Meitan County, Guizhou Province in China with about 0.1 m ground resolution. The covered area contains dense and tall buildings, sparse factories, mountains covered with forests, and some bare ground and rivers.
The dataset includes a complete aerial image set with ground truth depths for multi-view matching and disparities for stereo matching. In addition, we provided the cropped sub-image sets for facilitating deep learning.
We provided the whole aerial images and ground truth corresponding to the Aera 0 (yellow box). The virtual aerial image was taken at 550 m above the ground with 10 cm ground resolution. A total of 1,776 images (5376×5376 in size) were captured in 11 strips with 90% heading overlap and 80% side overlap, with corresponding 1,776 depth maps as ground truth. We set the rotational angles as (0,0,0), and two adjacent images therefore could be regarded as a pair of epipolar images. A total of 1,760 disparity maps along the flight direction also were provided.
Figure 1. The dataset.
We provided 8-bit RGB images and 16-bit depth/disparity maps with the lossless PNG format and text files that recorded the intrinsic and extrinsic parameters. Please see the “README.txt” file for a detailed explanation.
1.The whole aerial images and camera parameters (57 G)
2.The ground-truth depths for multi-view stereo (17.8 G)
3.The ground-truth disparities for two-view stereo (22.6 G)
(If you need multi-view dataset, please download 1 and 2, which are images and ground-truth depths respectively; if you need two-view stereo dataset, please download 1 and 3.)
We selected six representative sub-areas covering different scene types as training and test sets. A total of 261 aerial images of Areas 1/4/5/6 (red box) were used as the training set, and 93 images from Area 2 and Area 3 (red box) comprised the test set. For a direct application of the deep learning-based methods on the sub-dataset, we additionally provided a multi-view and a stereo sub-set by cropping the virtual aerial images into sub-blocks.
Multi-view Dataset: A multi-view unit consists of five images as shown in Figure 2. We cropped the overlapped pixels into the sub-block at a size of 768×384 pixels. A five-view unit yielded 80 pairs (400 sub-blocks) (Figure 3(a)). The depth maps were cropped at the same time.
Training set: 80×5×54 = 21600 sub-blocks
Test set: 80×5×17 = 6800 sub-blocks
The dataset was ultimately organized as Figure 3(b). The images, depth maps, and camera parameters were in the first level folder. The second level folders took the name of the reference image in a five-view unit; for example, 006_8 represented the eighth image in the sixth strip. The five sub-folders were named as 0/1/2/3/4 to store the sub blocks generated from cropping five-view images. Please see the “README.txt” file for a detailed annotation.
4.The cropped sub-set for multi-view stereo (12.6 G)
Stereo Dataset: Similar to the multi-view set, we cropped each image and disparity map into 768×384 pixels and obtained 154 sub-image block pairs in a two-view unit. The first level folder took the name of the left image in a stereo unit, and the second folder were named as Left/Right/Disparity to store the aerial image sub-blocks and disparities. The disparity values are corresponding to left reference. Please see the “README.txt” file for a detailed annotation.
Training set: 154×2×54 = 16632 sub-blocks (8316 pairs)
Test set: 154×2×17 = 5236 sub-blocks (2663 pairs)
5.The cropped sub-set for two-view stereo (8.96 G)
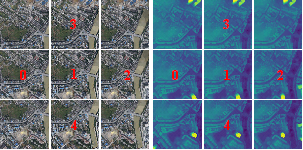
Figure 2. The images and depth maps from different viewpoints. A five-view unit took the Image with ID 1 as the reference image, the images with ID 0 and 2 in the heading direction and the images with ID 3 and 4 in the side strips as the search images. The three-view set consisted of images with ID 0, 1, and 2. In the stereo dataset, Image 1 and Image 2 were treated as a pair of stereo epipolar images.
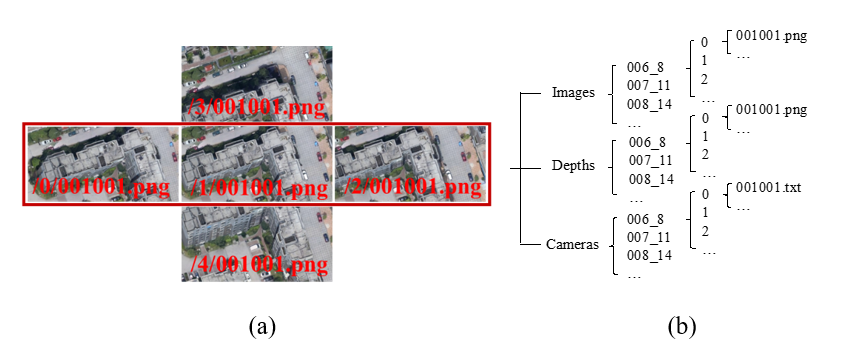
Figure 3. (a) A five-view sub-set with size of 768×384 pixels. The three sub-images in red rectangle comprise the three-view set. (b) The organization of images, depths, and camera files in the MVS dataset.