WHU-OMVS Dataset
1. Introduction
We built a synthetic oblique aerial image MVS dataset (the WHU-OMVS dataset) for the purpose of city-level 3D scene reconstruction. The WHU-OMVS dataset was rendered from the same base scene as the WHU-MVS dataset (Liu and Ji, 2020), extending the original nadir-view dataset to an oblique five-view stereo dataset.
Code: https://github.com/gpcv-liujin/Ada-MVS
2. Data and scene
Following the division of the WHU-MVS dataset, the data of Area #1/4/5/6 were used for the training. One slight difference is that both Area #2 and Area #3 were used for the testing in Liu and Ji (2020), whereas, in this work, Area #2 was treated as the validation region and Area #3 was the test region.

Fig. 1. The overall base scene for the WHU-MVS dataset.
The simulated cameras were arranged following a typical oblique five-view camera system. There is no displacement among the five cameras, that is, the five cameras are positioned to share the same projection center while looking in different directions. Camera #3 looks straight down, while the remaining four cameras have a tilt angle of 40°. Specifically, Camera #1 and Camera #5 look forward and backward, respectively, while Camera #2 and Camera #4 look to the right and left, respectively.
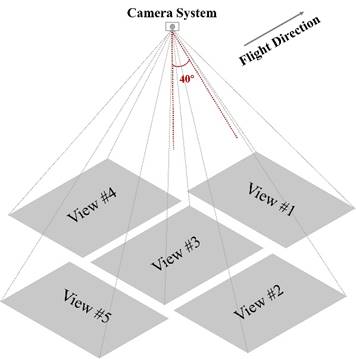
Fig. 2. The imaging view of each camera in the simulated oblique five-view camera system. Camera #3 captures the scene from a top-down perspective, while the other four cameras are tilted at a 40° angle and look in different directions.
3. About the Dataset
3.1. Train & Validation set
The training and validation set consist of rendered images with a size of 768 × 384 pixels in PNG format, with the corresponding depth maps in float EXR format, and the imaging parameters for each image are in TXT format.
The image overlap is 80% in the flight direction and 60% across the flight direction, with a flight height of 220 m above the ground and a ground sample distance (GSD) of approximately 10 cm in nadir view. In addition to the given settings, random jitter within ±0.5° was added to the rotation angle of each image to simulate the vibration that can occur in real exposure.
The training set has a total of 27460 images captured by five cameras from Areas #1/4/5/6, and 4500 images from Area #2 are used as the validation set.

Fig. 3. Examples of RGB images and depth maps from the five views in the training set with a size of 768 × 384 pixels. View #3 is the nadir view and the others are oblique views. The images from the same view have an overlap of 80% in the flight direction and 60% across the flight direction.
3.2. Test set
For the test set, a total of 268 images with a size of 3712 × 5504 pixels were rendered in five views, simulating the real-image size. The images were taken at 550 m above the ground with the same overlap as the training set, covering an area of about 850 × 700 m with a 10-cm ground resolution. In addition to the depth map and imaging parameters of each image, we also provide a DSM within the five-view overlapped area (580 × 580 m in size) with a GSD of 0.2 m, for evaluating the 3D reconstruction solution in object space.

Fig. 4. Examples of RGB images and depth maps from the five views in the test set. View #3 is the nadir view and the others are oblique views, with each image keeping a size of 3712 × 5504 pixels. The right is the ground-truth DSM covering the five-view overlap area of 580 × 580 m with a 0.2-m ground resolution.
3.3. Download
There are 3 folders in the dataset:
1. The train set (55.4 G)
2. The validation and sub-version test set (21.3 G)
3. The standard test set (47 G)
[Note]
1. Both the training and validation sets are collections of ready-made images of 768 × 384 pixels with ground-truth depth maps, which enables deep learning based MVS methods to be trained with mainstream GPU capacity.
2. The provided standard test set is a collection of large-frame aerial images with a size of 3712 × 5504 pixels with camera parameters. Except for the ground-truth depth maps and DSMs mentioned above, we also provide the ground-truth Mesh, 3D point clouds and Normal maps for test set. It is expected to perform a complete assessment of end-to-end 3D scene reconstruction using various practical solutions on this version.
3. We also provide a sub-version with an image size of 768 × 384 pixels for the test set (area #3). It is a ready-made version, which is similar to the training and validation set, for testing learning methods with mainstream GPU capacity.
Cite
If you found this work useful or used the provided dataset in your work, please cite our article:
@inproceedings{liu_novel_2020,
author = {Liu, Jin and Ji, Shunping},
title = {A Novel Recurrent Encoder-Decoder Structure for Large-Scale Multi-View Stereo Reconstruction From an Open Aerial Dataset},
booktitle = {2020 {IEEE}/{CVF} Conference on Computer Vision and Pattern Recognition ({CVPR})},
month = {June},
year = {2020},
pages = {6049--6058}
}
@inproceedings{LIU202342,
author = {Liu Jin, Gao jian, Ji Shunping, ZengChang, Zhang Shaoyi, Gong jianya},
title = {Deep learning based multi-view stereo matching and 3D scene reconstruction from oblique aerial images},
journal = {ISPRS Journal of Photogrammetry and Remote Sensing},
volume = {204},
year = {2023},
issn = {0924-27168}
doi = {https://linkinghub.elsevier.com/retrieve/pii/S0924271623002289}
}